Ceph Storage: Data Placement

Stockholm Public Library (source: https://pxhere.com/en/photo/641676)
จุดเด่นที่สุดอย่างหนึ่ง ในระบบ Ceph Storage คือ กระบวนการจัดเก็บข้อมูลภายใน (data placement) ที่แตกต่างจากระบบ distributed storage ทั้วไปที่มีการใช้ look up table เพื่อเก็บตำแหน่งของ object ใน cluster แต่ใน Ceph นั้นจะใช้การคำนวณแทน ทำให้ระบบไม่มี single point of failure และมี availability สูง นอกจากนี้ ยังมีความสามารถในการทำ replication หรือ ทำ erasure-coding กับข้อมูลที่เก็บลงไปอย่างอัตโนมัติอีกด้วย ทำให้ข้อมูลที่เก็บภายใน Ceph Storage นั้นมี durability สูง และเพื่อให้เข้าใจมากขึ้นว่าทำไมกระบวนการ data placement ดังกล่าวถึงทำให้ Ceph Storage มีความสามารถเหล่านั้น ในบทความนี้ผมจึงจะอธิบายลงรายละเอียดพอสังเขปเกี่ยวกับกระบวนการเก็บข้อมูลนี้ครับ
ในการจัดเก็บข้อมูลใน Ceph Storage ข้อมูลจะถูกจัดเก็บอยู่ในลักษณะของ object โดย object จะถูกเก็บลงไปในส่วนที่เรียกว่า Ceph OSD Node ซึ่งเป็นหน่วยเก็บข้อมูลภายใน Ceph Storage ครับ แต่ทว่ากระบวนการเก็บข้อมูลจริงๆ แล้วไม่ได้ง่ายดายเพียงแค่นั้น แต่เต็มไปด้วยกระบวนการต่างๆ มากมายหลายขั้นตอน ดังที่จะได้อธิบายเป็นลำดับต่อไป
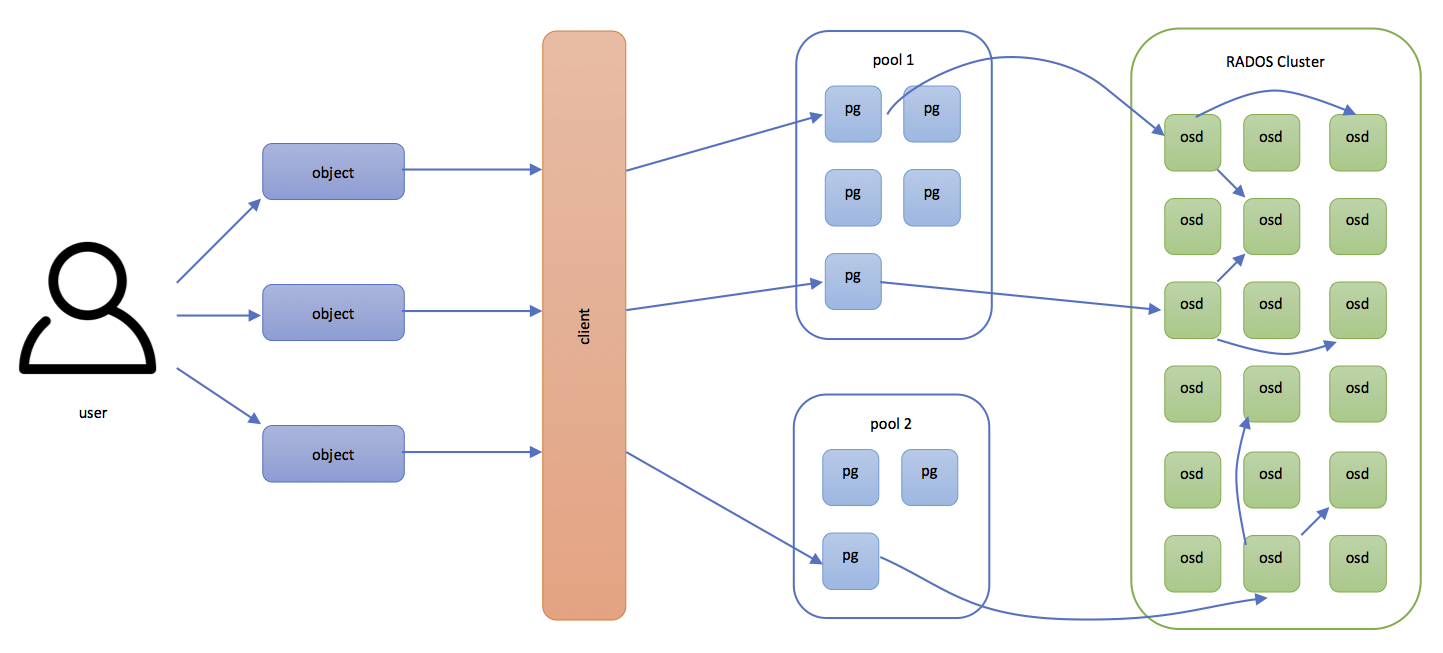
Ceph Data Placement Flow
ผู้ใช้ส่ง object ที่ต้องการเก็บ ไปยัง Ceph Client
จากแผนภาพด้านบนจะเห็นว่า ลำดับแรกในกระบวนการจัดเก็บข้อมูลลงใน Ceph Storage คือ ผู้ใช้ส่ง object ที่ต้องการจัดเก็บ รหัสประจำตัวของ object นั้น (หรือที่เรียกว่า object ID) และ pool ที่ต้องการให้นำ object นี้ไปจัดเก็บ ไปยัง Ceph Storage ผ่านทาง Ceph client เช่น object ข้อมูลลูกค้า บ.ไก่กา จำกัด และมี object ID = “บ.ไก่กา” นำไปเก็บใน pool ชื่อ “ข้อมูลลูกค้า” เป็นต้น
ลำดับต่อไป เมื่อผู้ใช้ส่ง object มายัง Ceph client แล้ว Ceph client จะทราบเพียงว่าผู้ใช้ต้องการเก็บ object ที่มี object ID ค่าหนึ่ง ลงไปใน pool ที่มีชื่อตามที่ระบุ client จะใช้ความรู้นี้ ผนวกกับ Cluster Map ที่ได้รับมาจาก Monitor node เพื่อคำนวณหาตำแหน่งในการเก็บ object ลงไปใน Ceph Storage โดยอาศัย CRUSH algorithm ผลลัพธ์ที่ได้จากการคำนวณคือ ID ของ OSD node ที่ต้องส่ง object นี้ไปจัดเก็บ
Pool และ Placement Group
จากภาพด้านบนสังเกตได้ว่า object จาก client นั้น ถูกเก็บอยู่เป็น pool ซึ่ง pool นี้เป็นเพียงกลุ่มจำลองขึ้นมา เพื่อให้จัดการกับ object เป็นกลุ่มๆ ได้ง่ายและสะดวกขึ้น โดยผู้ใช้สามารถกำหนดลักษณะการเก็บ object ใน pool แต่ละ pool ให้แตกต่างกันได้ตามความต้องการและคุณสมบัติของ object ที่เก็บลงไปในแต่ละ Pool ได้ ซึ่งมีอยู่ 2 ประเภทด้วยกัน คือ Replication Pool และ Erasure-Coding Pool
- Replication Pool คือ pool ที่จะทำการ replicate object ที่เก็บภายใน pool เป็นจำนวน replica ตาม Pool size ที่กำหนดตอนสร้าง pool ครับ (ซึ่งสามารถเปลี่ยนแปลงภายหลังได้ด้วยครับ) โดย pool ลักษณะนี้สามารถทนทานต่อการสูญเสียข้อมูลได้เท่ากับ pool size – 1 replica
- Erasure-Coding Pool คือ pool ที่จะทำการแบ่ง object ออกเป็น chunk เล็กๆ จำนวน K chunk และสร้าง coding chunk (หรือ parity/recovery chunk) อีกจำนวน M chunk โดย object สามารถสร้างขึ้นมาได้จาก K chunk ใดๆ ใน K+M chunk ทั้งหม นั่นคือ เมื่อนำ object จริงๆ จำนวน K chunk มาเทรวมกับ coding chunk จำนวน M chunk เป็น K+M chunk แล้ว ไม่ว่าจะหยิบ K chunk ใดออกมาก็ตามก็สามารถสร้าง object เต็มๆ ขึ้นมาได้เสมอครับ ซึ่งก็หมายความว่า Pool ลักษณะนี้สามารถทนทานต่อการสูญเสียข้อมูลได้เท่ากับจำนวน M chunk นั่นเองครับ
นอกจากเรื่องของลักษณะการเก็บข้อมูลแล้ว ผู้ใช้ยังสามารถกำหนด วิธีการกระจายข้อมูลในแต่ละ pool ได้อีกด้วย ยกตัวอย่างเช่น ในกรณีที่เป็น Replication Pool ผู้ใช้สามารถกำหนดได้ว่า ให้แต่ละ replica กระจายตัวอยู่คนละ rack กัน เพื่อป้องกันอันตรายจาก power supply ของ rack ล้มเหลว เป็นต้น
ภายใน pool ประกอบไปด้วย placement group (PG) จำนวนหนึ่ง ดังที่แสดงในแผนภาพบนสุ placement group นี้ทำหน้าที่เก็บ object หลายๆ object เข้าด้วยกันเป็นกลุ่มๆ เพื่อให้สะดวกต่อการจัดการและ balance load ของ Ceph OSD node แต่ละ node โดย 1 object จะสามารถอยู่ได้เพียง 1 PG เท่านั้น
คำนวณหา PG ID
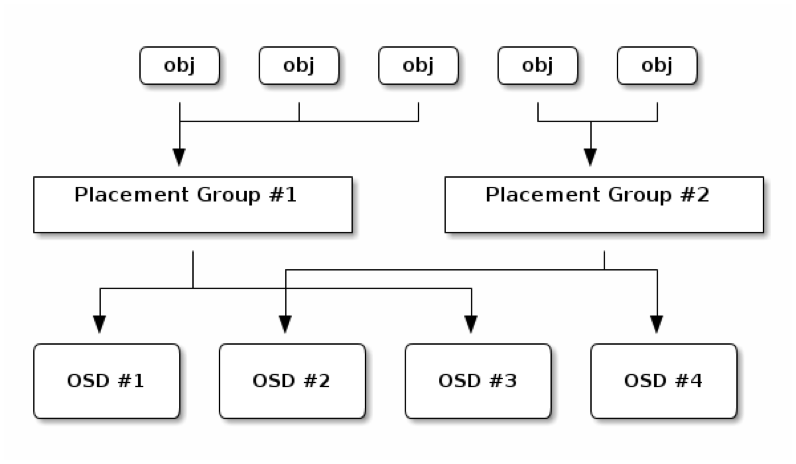
จากที่กล่าวไปแล้วว่า object นั้น ความจริงแล้วถูกเก็บอยู่ใน PG ซึ่งอยู่ภายใน pool อีกทีหนึ่งดังที่แสดงในแผนภาพด้านบน ดังนั้น ขั้นตอนต่อไปในกระบวนการเก็บข้อมูล คือ คำนวณหา PG ID นั่นเอง ซึ่งมีลำดับขั้นตอนดังนี้
- Hash object ID เพื่อให้ได้เป็นตัวเลขออกมา เช่น hash(“บ.ไก่กา”) = 1234
- นำผลลัพธ์จากข้อ 1 ไป modulo ด้วย จำนวน PG ทั้งหมดที่มีใน pool เป้าหมาย เช่น สมมติว่าใน pool “ข้อมูลลูกค้า” มี 128 PG ก็จะได้ว่า 1234 modulo 128 = 82 (modulo คือ การหาเศษของการหาร เช่น 27 modulo 4 = 3 เพราะ 27 ÷ 4 = 6 เศษ 3)
- หา ID ของ pool เป้าหมาย จาก pool name เช่น ID ของ pool “ข้อมูลลูกค้า” = 4
- นำผลลัพธ์จากข้อ 3 และ 4 มาต่อกันและคั่นด้วย “.” (จุด) และผลลัพธ์ที่ได้ คือ PG ID เช่น 4.82
ณ จุดนี้ Ceph client ทราบ จากการคำนวณแล้วว่า object “บ.ไก่กา” ต้องนำไปเก็บไว้ใน PG ที่มี PG ID = 4.82 แต่ทว่า ขั้นตอนยังไม่สิ้นสุดลงแต่เพียงเท่านี้ เพราะ Ceph client ยังไม่ทราบเลยว่า แล้ว PG ID = 4.82 นั้น อยู่ที่ Ceph OSD node ไหนกันแน่ ดังนั้น ขั้นตอนต่อไปคือ การคำนวณหา OSD node ID
คำนวณหา OSD node ID ด้วย CRUSH algorithm
ในการหา OSD node ID สำหรับ PG ID หนึ่งนั้น นอกจากจะจำเป็นต้องใช้ PG ID แล้วยังต้องการ Cluster Map เป็น input อีกด้วย โดยการคำนวณที่ว่านี้ทำโดยใช้ CRUSH algorithm
อย่างที่ได้อธิบายไปในเรื่องของ pool แล้วว่า ผู้ใช้สามารถกำหนดกฎการกระจายข้อมูลลงไปใน pool ได้ ซึ่งกฎที่ว่านั้น เรียกว่า CRUSH Ruleset โดย CRUSH Ruleset นี้ถูกประกาศไว้ใน CRUSH Map อันเป็นส่วนหนึ่งใน Cluster Map นั่นเอง
ในบทความนี้ผมขออนุญาตข้ามรายละเอียดของ CRUSH algorithm ไปนะครับ เพราะเดี๋ยวจะลงรายละเอียดจนเกินไป แต่สรุปได้ว่าหลังจากส่ง PG ID และ Cluster Map ให้ CRUSH algorithm แล้ว ผลลัพธ์ที่ได้ คือ OSD node ID ที่ Ceph client ต้องไปติดต่อเพื่อส่ง object ไปจัดเก็บ
กระบวนการเก็บข้อมูลลงไปใน OSD node
หลังจากที่ Ceph client ได้ OSD node ID และส่ง object ไปยัง OSD node นั้นๆ แล้ว ขั้นตอนต่อไป คือ การกระจาย object ออกไปยัง OSD node อื่นๆ เพื่อความปลอดภัยของข้อมูลตามลักษณะการเก็บ object ที่กำหนดไว้ใน Pool นั้นๆ โดยทุกส่วนของ object ที่กระจายไปยัง OSD node อื่นๆ ล้วนแล้วแต่เก็บอยู่ภายใต้ PG ID เดียวกันทั้งสิ้น
กรณีที่ 1: Replication Pool
กระบวนการเก็บข้อมูลสำหรับในกรณีที่เป็น Replication Pool ที่มี size = 3 จะเกิดขึ้นดังแผนภาพด้านล่าง
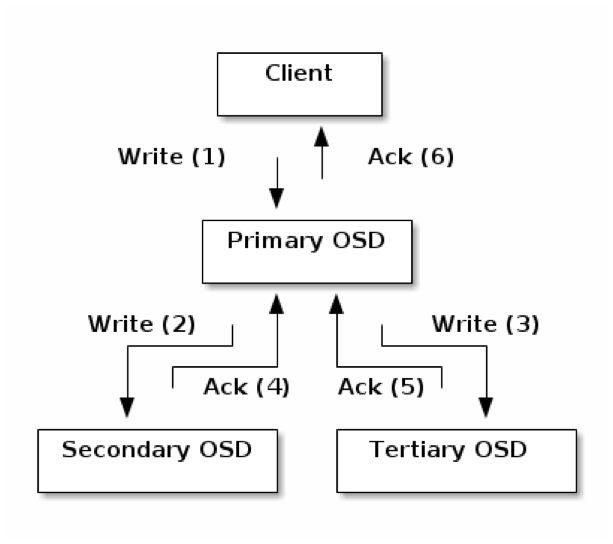
แผนภาพด้านบนแสดงให้เห็นว่า กระบวนการเริ่มต้นจาก Ceph client ส่ง object มาเก็บไว้ใน PG ใน OSD node ตาม ID ที่ได้มาจากการคำนวณ CRUSH ซึ่ง OSD node นี้เรียกว่า Primary OSD ของ PG นี้
หลังจากที่ Primary OSD เก็บ object เรียบร้อยแล้ว จะยังไม่แจ้ง client ทันที แต่จะคำนวณ CRUSH algorithm อีกรอบหนึ่ง เพื่อหา OSD node ID ของ Secondary OSD และ Tertiary OSD ออกมา และทำการส่ง object ไปยัง OSD node เหล่านั้น
จากนั้น Primary OSD จะรอให้ Secondary และ Tertiary OSD เก็บ object ให้เสร็จเรียบร้อยแล้วแจ้งกลับมาที่ตนว่าสำเร็จแล้ว จากนั้น Primary OSD จึงจะแจ้งกลับไปยัง client ว่ากระบวนการเก็บ object เสร็จสิ้นแล้ว สำหรับ Replication Pool กระบวนการเก็บข้อมูลใน Ceph Storage ก็จบลง ณ จุดนี้
กรณีที่ 2: Erasure-Coding Pool
สำหรับในกรณีของ Erasure-Coding Pool ที่มี K = 3 และ M = 2 กระบวนการจัดเก็บข้อมูลจะเกิดขึ้นดังแผนภาพด้านล่างนี้
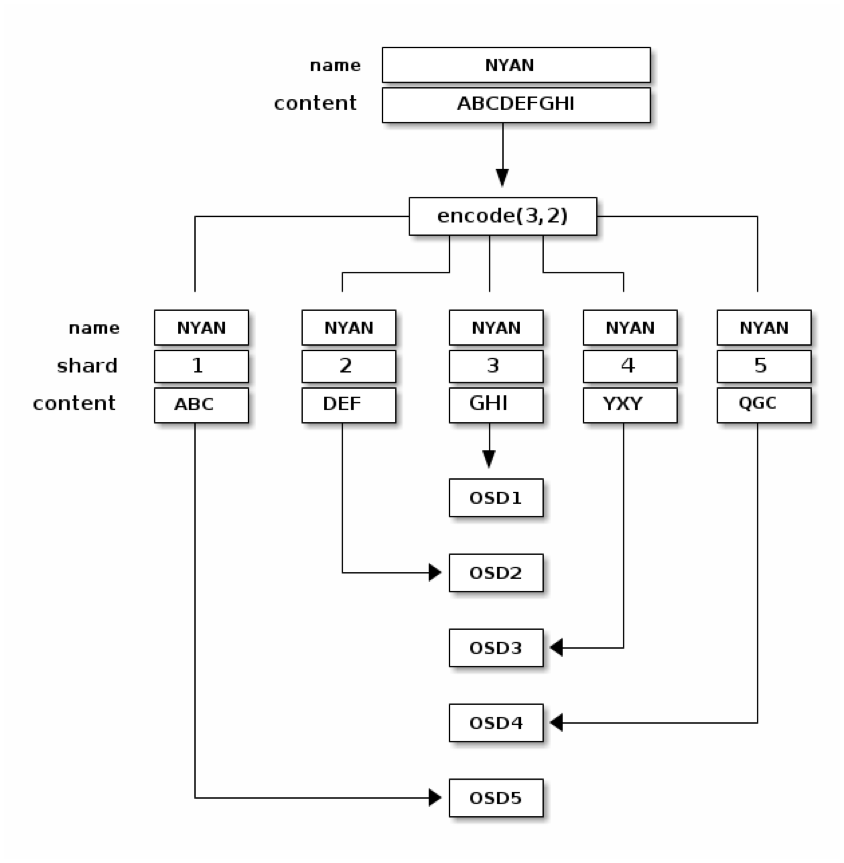
แผนภาพด้านบนตัดตอนมาถึงจังหวะที่ object ชื่อ “NYAN” และมีข้อมูล “ABCDEFGHI” มาถึง Primary OSD แล้วนะครับ ซึ่งก็เช่นเดียวกับกรณีของ Replication Pool Primary OSD คือ OSD node ที่มี ID ตามที่คำนวณได้จาก CRUSH algorithm ที่ Ceph client
ขั้นตอนแรก หลังจากที่ Primary OSD ได้รับ object มาแล้ว คือ แบ่ง object ออกเป็น 3 chunk และสร้าง coding chunk ขึ้นมา 2 chunk (encode(3,2) ตามที่แสดงในแผนภาพ)
จากนั้น แต่ละ chunk จะถูกส่งไปเก็บยังแต่ละ OSD node รวมทั้งตัว Primary OSD เอง
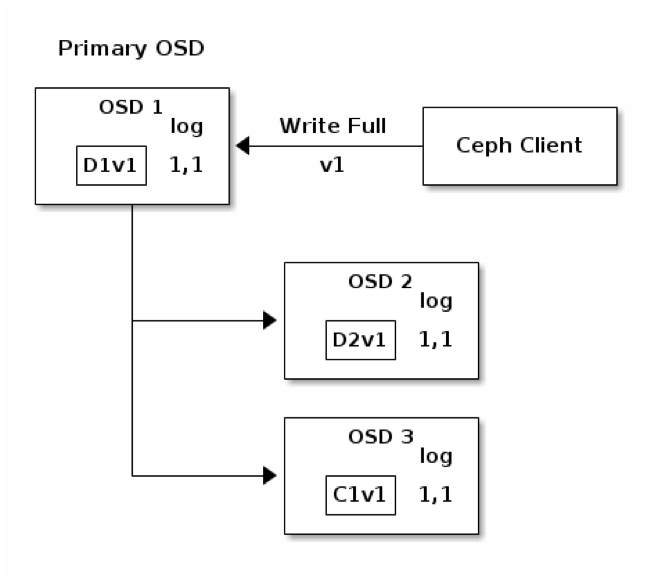
แผนภาพนี้แสดงถึงขั้นตอนการเก็บข้อมูลใน Erasure-Coding Pool ที่มี K = 2 และ M = 1 โดย object ถูกแบ่งออกเป็น 3 chunk คือ D1v1 (data chunk หมายเลข 1 version 1), D2v1, และ C1v1 (coding chunk หมายเลข 1 version 1) ซึ่งจะเห็นว่า แต่ละ chunk ถูกกระจายไปเก็บยัง OSD node ต่างๆ node ละ chunk ดังที่ได้อธิบายไปก่อนหน้านี้ แต่ที่มีเพิ่มเติมมา คือ log 1,1 ที่ด้านขวาของแต่ละกล่อง OSD ซึ่งเป็น Placement Group Log ที่เก็บไว้ในแต่ละ OSD node โดย log 1,1 หมายความว่า epoch 1, version 1
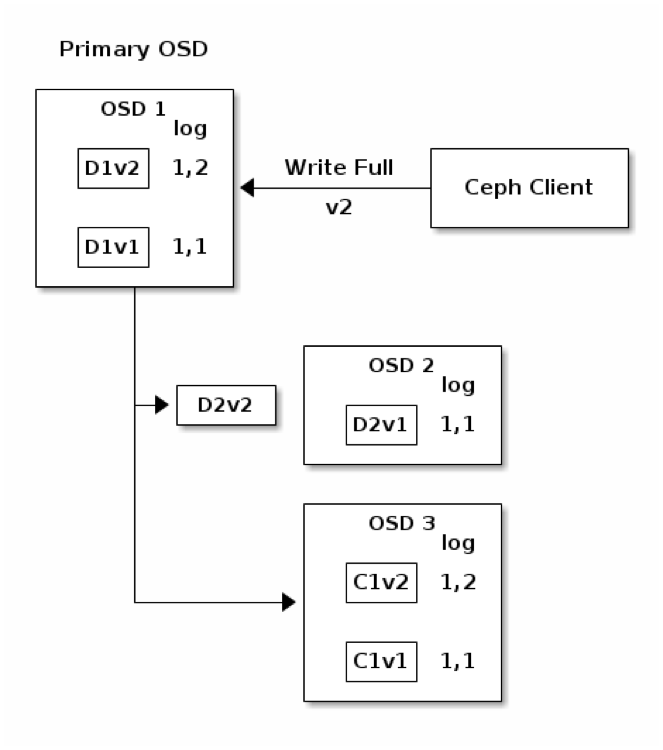
จากแผนภาพด้านบน แสดงกรณีที่ object มีการแก้ไขเกิดขึ้น จะพบว่า Primary OSD สร้าง chunk D1v2, D2v2, และ C1v2 ส่งไปยัง Secondary และ Tertiary OSD เพื่อจัดเก็บในลักษณะ asynchronous กล่าวคือ chunk ของข้อมูลจะถูกส่งไปหาทั้ง 2 OSD พร้อมกันโดยไม่ต้องรอให้ OSD ใด OSD หนึ่งเสร็จก่อน จากนั้นจึงรอผลลัพธ์จากทั้งคู่ โดยที่แต่ละ OSD จะมีการสร้าง Placement Group Log Entry ใหม่ขึ้นมา คือ 1,2 (epoch 1, version 2) ไว้คู่กับ chunk version 2 ที่ส่งมาใหม่
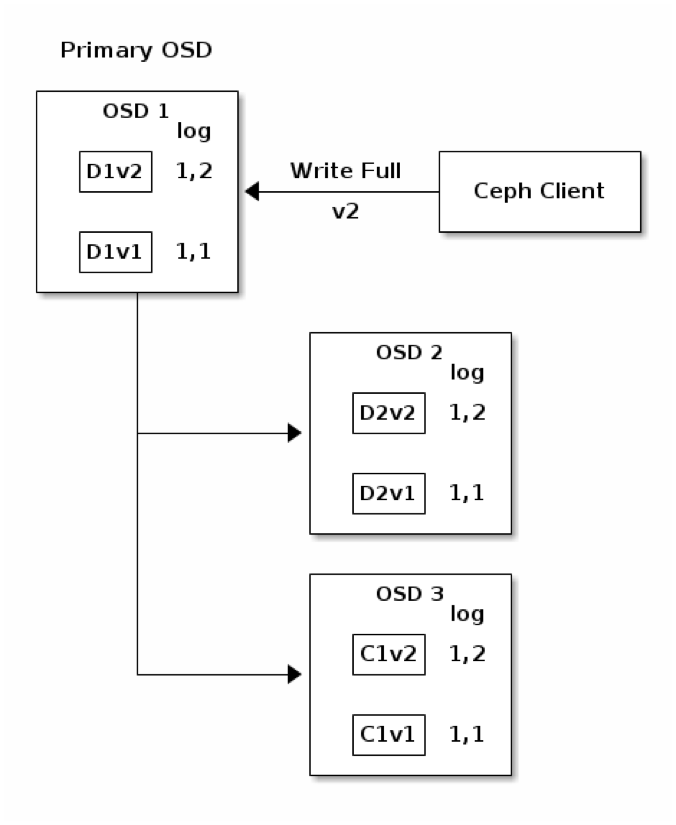
เป็นที่สังเกตว่า chunk version เก่าจะยังไม่ถูกลบทิ้งทันที แต่จะรอจนกว่าทุก OSD เก็บ chunk version ใหม่นี้เสร็จเรียบร้อยแล้วก่อน จึงทำการลบ chunk version พร้อมทั้ง Placement Group Log Entry 1,1 ออก ดังที่แสดงในแผนภาพถัดไป
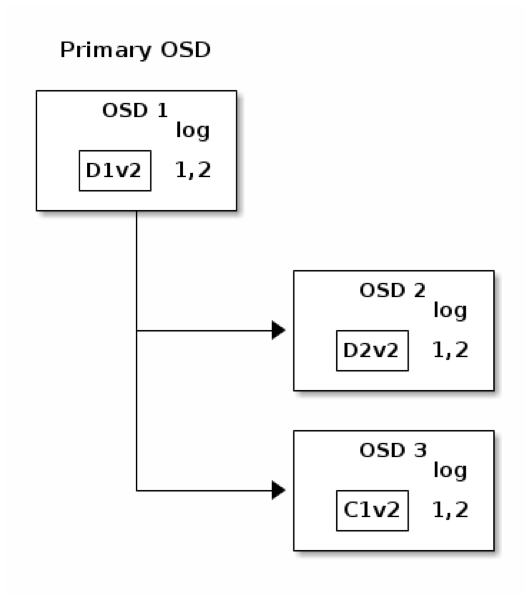
โดยสรุปแล้ว กระบวนการเก็บข้อมูลลงใน Ceph Storage พอสังเขปดังที่เป็นอธิบายไปข้างต้นนี้ สามารถสรุปได้เป็น 8 ขั้นตอน ดังนี้ครับ
- ผู้ใช้ส่ง object ไปยัง Ceph client
- Ceph client คำนวณหา PG ID
- Ceph client คำนวณหา OSD node ID โดยใช้ CRUSH algorithm
- Ceph client ส่ง object ไปยัง Primary OSD (OSD node ที่มี ID ที่ได้จากข้อ 3)
- Primary OSD คำนวณ OSD node ID อื่นๆ โดยใช้ CRUSH algorithm
- Primary OSD กระจาย object ไปยัง OSD node อื่นๆ ตามที่คำนวณได้จากข้อ 5 โดยเก็บอยู่ภายใต้ PG ID เดียวกันทั้งหมด (PG ID ที่ได้จากข้อ 2)
- แต่ละ OSD node แจ้งกลับไปยัง Primary OSD ว่าเก็บข้อมูลเสร็จสิ้นแล้ว
- Primary OSD แจ้งกลับไปยัง Ceph client ว่าเก็บข้อมูลเสร็จสิ้นแล้ว
สำหรับผู้ที่สนใจเกี่ยวกับ Ceph Storage เพิ่มเติม สามารถติดตามอ่านบทความตอนก่อนหน้านี้ได้ที่นี่ครับ
- แนะนำ Ceph Storage – distributed storage รูปแบบใหม่ที่น่าสนใจสำหรับองค์กร
- Ceph RADOS series: Part I, Part II, Part III, Part IV
- Ceph Client series: Part I, Part II, Part III
เกี่ยวกับ Throughwave Thailand
![]()
Throughwave Thailand เป็นตัวแทนจำหน่าย (Distributor) สำหรับผลิตภัณฑ์ Enterprise IT ครบวงจรทั้ง Server, Storage, Network และ Security พร้อมโซลูชัน VMware และ Microsoft ที่มีลูกค้าเป็นองค์กรชั้นนำระดับหลายหมื่นผู้ใช้งานมากมาย โดยทีมงาน Throughwave Thailand ได้รับความไว้วางใจจากลูกค้าจากทีมงาน Engineer มากประสบการณ์ ที่คอยสนับสนุนการใช้งานของลูกค้าตลอด 24×7 ร่วมกับ Partner ต่างๆ ทั่วประเทศไทยนั่นเอง https://www.throughwave.co.th





